

Key points
- The solution to insufficient real-world data is to produce synthetic data by artificially generating millions of simulations.
- Synthetic data is an important component in training artificial-intelligence and machine-learning models, in addition to assisting in privacy-compliant data sharing, software development, system testing, object labelling, and 3D simulation.
- Synthetic data is a significant accelerator for private companies to compete in a data-heavy world.
- Since synthetic data is artificially generated, fewer data governance issues arise.
During a snowstorm, how would an autonomous vehicle differentiate between the red lights of an ambulance and that of a stop light? The vehicle would rely on its training from real-world examples, much like it does when stopping for a pedestrian who is crossing the road on a sunny day. The issue, however, is that while the vehicle may have seen a multitude of real-world examples of stop lights when its model was trained, it may have seen significantly fewer examples of ambulances in a snowstorm, causing it to infer the presence of a stop light. This could generate a costly decision to abruptly stop instead of safely pulling to the side of the road.
The solution to the asymmetry in real-world data in this scenario is to artificially produce millions of simulations of emergency vehicles in a snowstorm to train the system. In other words, use synthetic data to simulate the ‘corner case’. Beyond these corner cases, synthetic data can also simulate conditions that have not occurred but have the potential to occur. This helps resolve data-availability bottlenecks, reduces costs of collecting data, and increases the pace of innovation.
Finite real-world data
As use cases for artificial intelligence (AI) and machine learning (ML) proliferate, algorithm developers are increasingly faced with a lack of real-world data pertinent to their specific uses. With incremental algorithm-performance improvements requiring vastly more data, synthetic data has emerged as an impactful solution. In fact, Gartner predicts that 60% of all data used in the development of AI will be synthetic by 2024,[1] while a 2022 paper states that the stock of high-quality language data is likely to be exhausted before 2026.[2]
Beyond AI and ML training and testing, synthetic data is assisting in privacy-compliant data sharing, software testing and development, system testing, object labelling, and 3D simulation. Health-care providers are leveraging synthetic data to create statistically comparable models without any actual patient information. In return, the model is used across the organisation to maximise resource allocation, improve patient outcomes, and reduce cost. Financial institutions can better underwrite risk and prevent fraud by utilising synthetic data to recreate and analyse exponentially more ‘what-if’ scenarios. Industrial companies are using synthetic data in manufacturing, supply-chain logistics and systems testing to improve efficiency and reduce production downtime.
From an investment standpoint, we are looking at both public and private companies while ensuring companies across industries are making the necessary investments to harness the power of synthetic data. Interesting opportunities include developers of simulation software that can generate synthetic data, data warehousing/management tools to manage greater data volumes, and the hardware infrastructure needed to power the generation and storage of this data. Since 2018, over $1.6 billion has been invested in 200+ synthetic-data start-ups according to data from Pitchbook.
Synthetic data – private market view
Algorithms need vast amounts of real-world training data from which to learn. However, as mentioned previously, relying on real-world data for this purpose is not practical, cost effective, or time efficient. While not new, the ability to produce synthetic data in an inexpensive and timely manner is reaching a critical point in terms of impact potential. According to Alumni Ventures, approximately 80% of time spent on building ML models is dedicated to data management and labelling, with 10-15% of a start-up’s revenue spent ensuring this training data is accurate and properly labelled.[3] This data-related bottleneck has hindered the pace of innovation, limiting the profitability and growth trajectory of many younger companies seeking to build industry-disrupting AI products, as they may lack the necessary time, resources and capital to do so.
Many believe that synthetic data can be part of the solution as it offers several advantages, including its ability to overcome some of the challenges related to privacy, data ownership, and model attribution. It is also thought to be more cost effective, less biased, and more customisable than real-world data. Additionally, this data may help countries with more stringent privacy policies compete with countries who have more relaxed privacy policies around collecting data. The CEO/Cofounder of Datagen, a private company in the space, further highlighted the excitement surrounding the potential of synthetic data when he claimed that “…the total addressable market of synthetic data and the total addressable market of data will converge.”[4]
The growing interest from the venture-capital community in synthetic data start-ups, as evidenced by the extent of the investment in the area in recent years seen in the graph below, is a testament to its potential. The first wave of start-ups working to generate synthetically derived data largely focused on the autonomous-vehicle industry, yet many have since realised the potential of the technology and how instrumental it can be in training today’s AI algorithms and ML systems across various verticals. Andreesen Horowitz has identified the need to manually label datasets as one of the largest barriers to the widespread adoption of AI.[5] Data-annotation companies, such as Scale AI, work to clean, structure, label and package large datasets. Other start-ups in the space that have recently raised large funding rounds include those focusing on areas such as AI decision-making and 3D environment generation.
Venture capital funding: Synthetic data
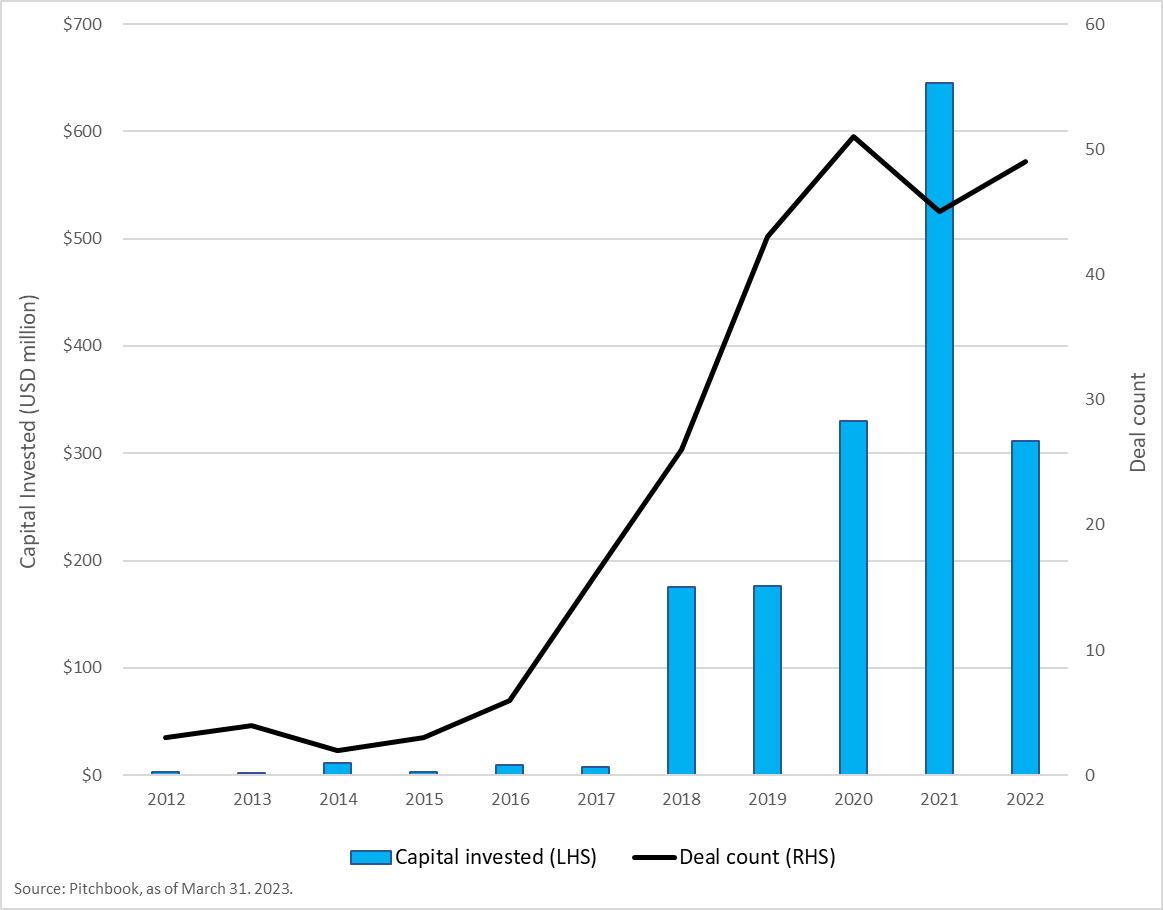
Despite limitations, risks and ethical concerns, some of which are discussed below, synthetic data offers several benefits for start-ups, including accelerated product development and innovation, reduced reliance on massive amounts of real-world data, and cost savings. As the AI and ML markets continue to grow, synthetic data will play an increasingly important role in generating realistic data, training and validating models, and overcoming other data-related challenges across various industries.
Societal impact
It is difficult to talk about AI without considering its social impacts, in terms of jobs affected as well as the fairness and transparency of models and outcomes, and synthetic data is no different. However, with synthetic data there are fewer risks associated with its source. Its data is not directly traceable to individuals and so does not run the risk of infringing on an individual’s rights to their own data, such as the right to be forgotten. Consequently, there may also be less legal risk—if data is not identifiable it is less likely to fall under the scope of the European Union’s General Data Protection Regulation or the less stringent US Federal Privacy Act, or even intellectual property or copyright standards. In 2016, Pokémon took legal action against a website host for copyright infringement over Pikachu images, and while the damages were not material, it was legally successful despite the website host having policies and procedures in place and a content-moderation team. Synthetic data can significantly reduce these risks.
The applications for synthetic data, however, are overwhelmingly positive. It can be used to create hypothetical scenarios to help companies and individuals prepare for specific events, whereas in real life it may take decades and huge costs to collect this data, or the event may not have occurred. This could have benefits in flight simulation or cybersecurity defence, to name just two examples. Synthetic data can also be used to address two significant and known technology risks. The first is content moderation, which has become costly for some social-media companies. The use of synthetic data reduces the role of humans in this process, as created data can be accurately labelled at the start of the process. This can both reduce the mental toll of viewing potentially disturbing content, as well as the subjectivity of human judgement in classifying content after it has been made available. The second is that it may reduce the biases associated with trained AI models, whereby systems learn from human decisions, which are not always optimal. This has been well documented in job-application processes, often to the detriment of female or minority applicants. The creation of data may be a way to avoid exacerbating existing biases.
However, synthetic data is not without social risk. While it can reduce some of the risks discussed above, synthetic data still relies on original data to be generated, and so these risks are not fully eradicated. There is also the risk that bad actors generate synthetic data with malicious intent, or that consumers misunderstand or are misled about synthetic and actual data.
Conclusion
Synthetic data is an important tool as the real world increasingly interacts with algorithms, AI and data models. Generating synthetic data is proven to be a significant cost and time saver, but more importantly decreases risk, ensures a normal distribution of inputs, and helps understand the unknown. In our view, those companies that can generate high-quality synthetic data and implement it in novel ways are set to have a competitive edge in a data-first world.
[1] https://blogs.gartner.com/andrew_white/2021/07/24/by-2024-60-of-the-data-used-for-the-development-of-ai-and-analytics-projects-will-be-synthetically-generated/
[2] https://doi.org/10.48550/arXiv.2211.04325
[3] https://www.av.vc/blog/venture-deep-dives-synthetic-data
[4] https://www.forbes.com/sites/robtoews/2022/06/12/synthetic-data-is-about-to-transform-artificial-intelligence/?sh=9dc0e1c75238
[5] https://a16z.com/2020/02/16/the-new-business-of-ai-and-how-its-different-from-traditional-software-2/
Authors

Newton secular research team
Secular research team

Newton private markets team
Private markets team

Newton responsible investment team
Responsible investment team
This is a financial promotion. These opinions should not be construed as investment or other advice and are subject to change. This material is for information purposes only. This material is for professional investors only. Any reference to a specific security, country or sector should not be construed as a recommendation to buy or sell investments in those securities, countries or sectors. Please note that holdings and positioning are subject to change without notice.
Important information
This material is for Australian wholesale clients only and is not intended for distribution to, nor should it be relied upon by, retail clients. This information has not been prepared to take into account the investment objectives, financial objectives or particular needs of any particular person. Before making an investment decision you should carefully consider, with or without the assistance of a financial adviser, whether such an investment strategy is appropriate in light of your particular investment needs, objectives and financial circumstances.
Newton Investment Management Limited is exempt from the requirement to hold an Australian financial services licence in respect of the financial services it provides to wholesale clients in Australia and is authorised and regulated by the Financial Conduct Authority of the UK under UK laws, which differ from Australian laws.
Newton Investment Management Limited (Newton) is authorised and regulated in the UK by the Financial Conduct Authority (FCA), 12 Endeavour Square, London, E20 1JN. Newton is providing financial services to wholesale clients in Australia in reliance on ASIC Corporations (Repeal and Transitional) Instrument 2016/396, a copy of which is on the website of the Australian Securities and Investments Commission, www.asic.gov.au. The instrument exempts entities that are authorised and regulated in the UK by the FCA, such as Newton, from the need to hold an Australian financial services license under the Corporations Act 2001 for certain financial services provided to Australian wholesale clients on certain conditions. Financial services provided by Newton are regulated by the FCA under the laws and regulatory requirements of the United Kingdom, which are different to the laws applying in Australia.



Comments